

Saviez-vous qu’il est possible de créer ses propres visuels dans Power BI en Python 🐍 ?
Mais pourquoi vouloir s’embêter avec du code Python alors que la Marketplace offre déjà tant de visuels supplémentaires ? 🤔
Voici mon expérience : récemment, un client m’a demandé de comparer une entreprise à la moyenne du marché sur six axes d’analyse. Malheureusement, aucun visuel natif n’était satisfaisant pour ce besoin. J’ai donc pensé à un Radar plot et j’ai téléchargé celui de Microsoft depuis la marketplace… avant de réaliser à quel point il manquait de flexibilité. Pas le temps (ni le budget) de (faire) développer un Custom Visual, alors j’ai jeté un œil du côté des visuels Python.
Avec seulement quelques lignes de code, et l’aide de ChatGPT 💡, j’ai réussi à créer un Radar plot entièrement personnalisé. Non seulement la solution a répondu aux attentes, mais elle été rapide à mettre en place et prouve que les visuels Python peuvent combler dans certains cas les limites des visuels standards dans Power BI.
Dans cet article, je vous montre pas à pas comment créer de tels visuels Python dans Power BI pour réaliser des visualisations avancées sans être un expert du développement — tout en vous mettant en garde de certaines limitations (oui, il y en a). Bonne lecture ! 🚀
Quand et pourquoi utiliser des visuels Python
Python est aujourd’hui l’un des langages les plus populaires en Data Science et en Data Analysis, notamment grâce à ses librairies puissantes comme NumPy, Pandas, Matplotlib, Scikit-learn, etc. Il se prête aussi bien à l’exploration de données, à la modélisation qu’à la production de visualisations avancées et à la création de modèle d’Intelligence Artificielle 🤩. Avec une communauté très active et une courbe d’apprentissage assez douce, Python est devenu un incontournable pour quiconque veut dynamiser ses projets data.
Je vois pour moi 2 raisons principales à intégrer des visuels en Python dans mes rapports Power BI :
- Non adéquation de visuel standard ou de la place de marché avec ce que je souhaite visualiser
- Richesse des librairies d’analyse et de visualisation de données de Python
Il existe déjà un certain nombre de visuels standards dans Power BI, ainsi que les Custom visuals disponibles sur la place de marché. Cependant, dans certains cas on peut se retrouver sans solution ni alternative, comme pour le Radar plot dans mon histoire. C’est là que les visuels Python peuvent offrir une excellente alternative.
D’un autre côté, le langage Python est une référence en matière de bibliothèques de visualisation comme Matplotlib et Seaborn. Elles permettent notamment :
- De personnaliser en profondeur les couleurs, formes et légendes
- D’accéder à des visuels avancés
- De manipuler et d’analyser les données, parfois en réalisant des calculs statistiques complexes
De plus, quitte à utiliser Python dans un visuel, rien n’empêche d’y incorporer des calculs, aggrégations, statistiques et autres, en se servant d’autres librairies phares telles que Pandas, Numpy, Scikit Learn, etc.
Voilà pour les raisons. Voyons pour le comment maintenant.
Installer Python sur sa machine
Trève de blabla, avant de pouvoir utiliser un visuel Python dans Power BI Desktop, vous devez installer Python sur votre machine, puis indiquer le chemin d’accès à l’exécutable dans Power BI. Si vous ne l’avez pas déjà fait, voici les grandes étapes :
- Téléchargez et installez Python (idéalement la version 64 bits) depuis le site officiel de Python par exemple. Pour ma part, j’ai installé Winpython pour Windows
- Ouvrez Power BI Desktop, rendez-vous dans Fichier > Options et paramètres > Options > Création de scripts Python
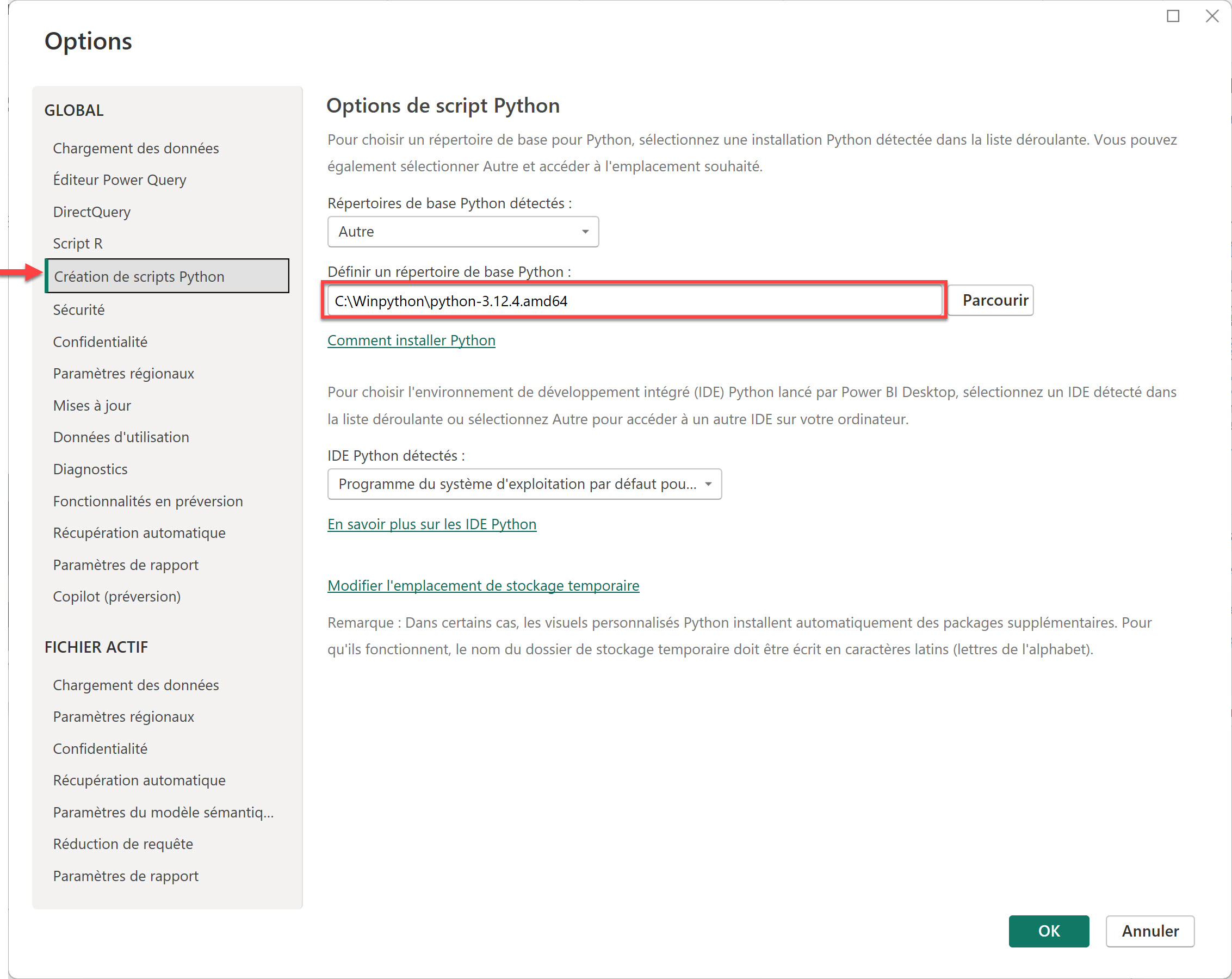
- Sélectionnez le chemin d’accès menant à l’exécutable Python (par exemple : C:\Users\votreNom\AppData\Local\Programs\Python\Python39\python.exe)
- Validez
Pour en savoir plus, consultez la documentation officielle de Microsoft.
Une fois Python configuré, vous pourrez non seulement utiliser les visuels Python, mais aussi créer et exécuter des scripts Python dans Power Query (je précise que ce n’est pas le sujet ici).
Bibliothèques Python utilisables dans Power BI
Ces librairies sont supportés dans Power BI :
- matplotlib
- numpy
- pandas
- scikit-learn
- scipy
- seaborn
- statsmodels
Il y en a plus dans Power BI Service apparemment. Celles qui nous intéressent en particulier pour créer des visuels sont :
Matplotlib
Matplotlib permet de concevoir tout un panel de graphiques (barplots, scatterplots, radar plots, etc.) tout en contrôlant finement chaque élément (couleurs, axes, titres, etc.).
Seaborn
Seaborn propose des designs plus esthétiques et intègre des fonctionnalités statistiques (heatmaps, analyses de distributions, etc.). Elle est particulièrement appréciée pour sa simplicité et son rendu visuel plus “propre”.
Création d’un visuel Python – Etape par étape
✅ Installer Python en local
✅ Préparer vos données : Chargez-les dans Power BI (via Power Query) et nettoyez-les si nécessaire (suppression des doublons, formatage des dates, etc.).
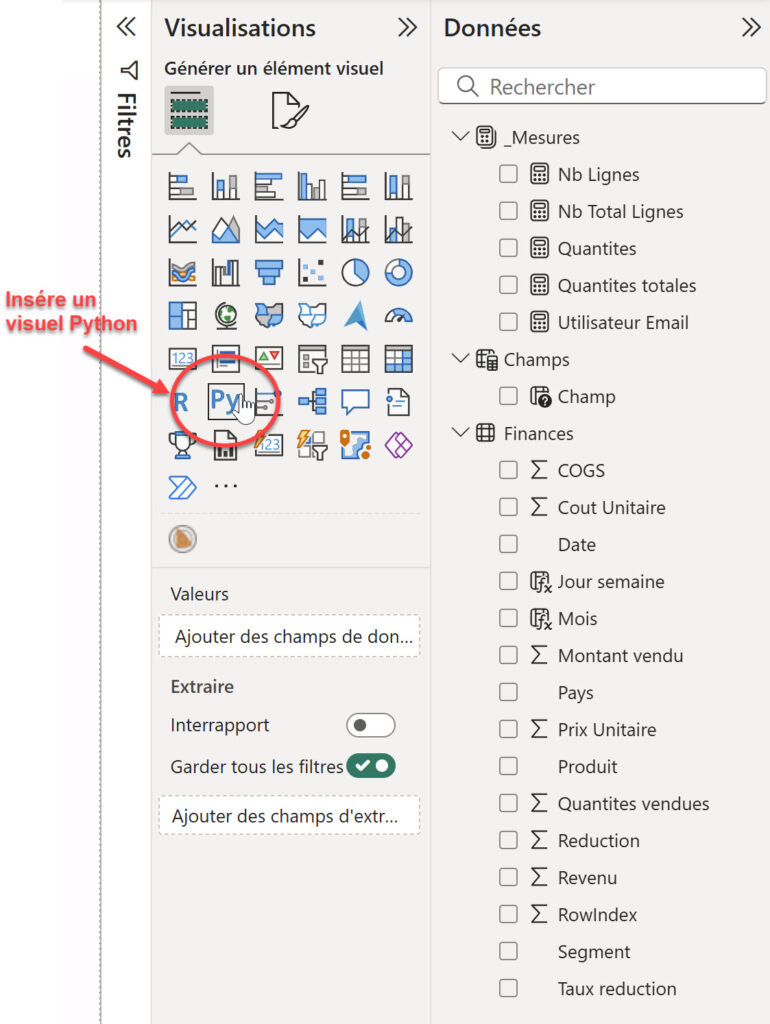
✅ Ajouter un visuel Python : Dans Power BI Desktop, sélectionnez le visuel Python. Vous verrez alors un éditeur où coller votre script Python.
✅ Glisser les champs à visualiser dans le visuel Python
✅ Rédiger un script et le copier-coller dans l’éditeur du visuel
✅ Patienter un peu, il mettra plus de temps à s’afficher que les visuels standards
Comment rédiger son script Python ?
Si comme moi vos souvenirs de Python sont déjà lointoins où que vous n’avez jamais eu l’occasion d’écrire une seule ligne de code dans ce langage, vous pouvez solliciter ChatGPT pour obtenir un exemple de script correspondant à vos besoins. Par exemple :
« Peux-tu écrire un script Python pour créer un barplot qui affiche les quantités vendues par produit? »
💡Préciser bien que vous écrivez un script pour un visuel Power BI, ainsi il intègrera la syntaxe attendue.
ChatGPT fournira un code de base, que vous pourrez ensuite personnaliser. Voici un extrait simplifié :
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Exemple de préparation des données (dans Power BI, "dataset" vous est fourni tel quel)
# dataset = dataset.drop_duplicates()
# Agrégation des quantités vendues par produit
df_bar = dataset.groupby("Produit")["Quantites vendues"].sum().reset_index()
# Création de la figure
plt.figure(figsize=(10, 6))
# Barplot avec Seaborn
sns.barplot(
data=df_bar,
x="Produit",
y="Quantites vendues",
color="blue"
)
# Titre et rotation des étiquettes en abscisse
plt.title("Quantités vendues par produit", fontsize=14)
plt.xticks(rotation=45, ha="right")
# Affichage du graphe
plt.tight_layout()
plt.show()
Intégration et exécution
- Copiez-collez le script dans l’éditeur Python de Power BI, qui apparaît lorsqu’on clique sur le visuel Python
- Validez et laissez Power BI exécuter le script localement (d’où l’importance d’avoir Python installé)
💡Important : veillez à bien ajouter les champs utilisés par le script dans le visuel Python !
Quelques exemples de visuels Python
Afin de montrer les possibilités de personnalisation offertes par ces derniers… Et comment tirer parti des packages de statistiques des données puissants de Python.
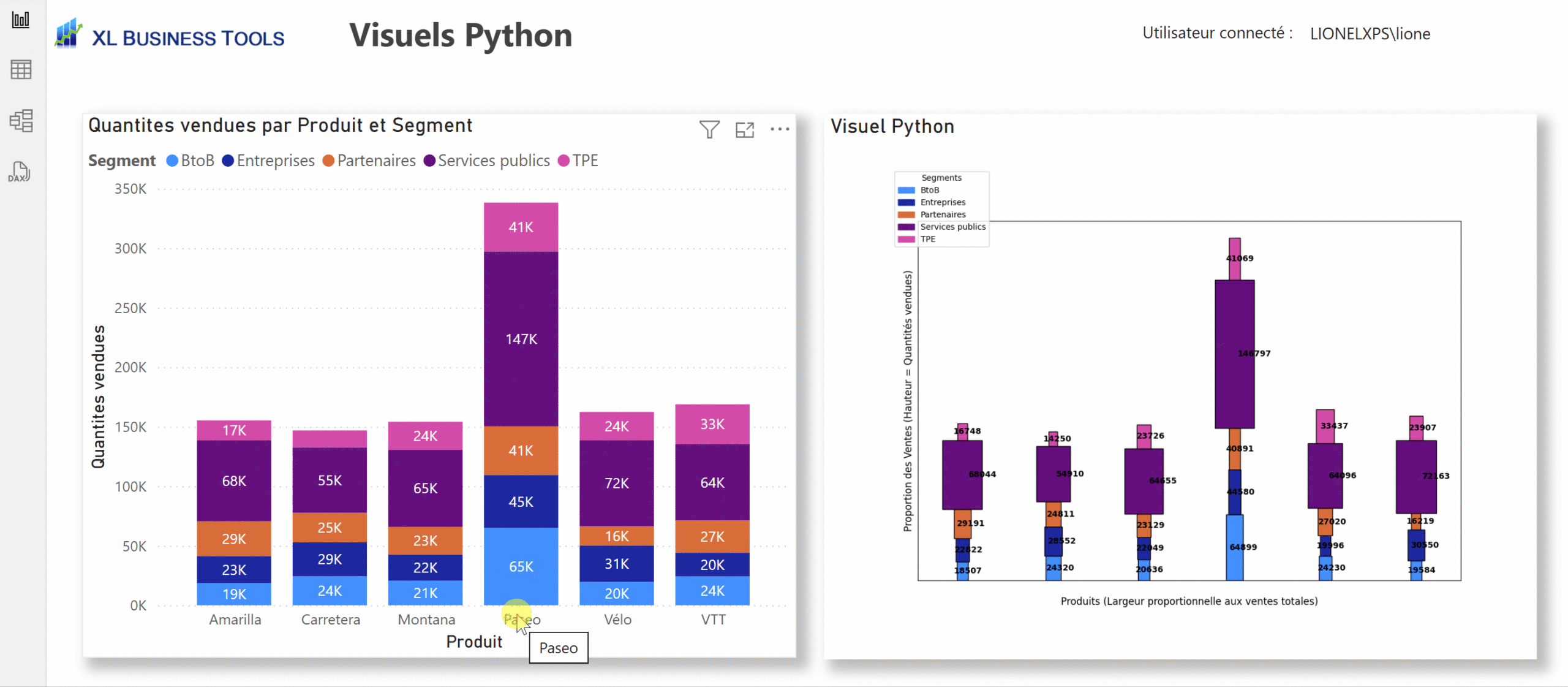
Histogramme de Marimekko
#*****************************************************************************************************
# Visuel Marimekko Chart
#*****************************************************************************************************
# Importation des bibliothèques
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# Agrégation des données : total des quantités vendues par Produit et Segment
df_marimekko = dataset.groupby(["Produit", "Segment"])["Quantites vendues"].sum().reset_index()
# Normalisation pour calculer la largeur et la hauteur
df_marimekko["width"] = df_marimekko.groupby("Produit")["Quantites vendues"].transform(lambda x: x / x.sum())
df_marimekko["height"] = df_marimekko["Quantites vendues"] / df_marimekko["Quantites vendues"].sum()
# Définition des couleurs fixes pour chaque segment
segment_colors = {
"BtoB": "#118DFF",
"Entreprises": "#12239E",
"Partenaires": "#E66C37",
"Services publics": "#6B007B",
"TPE": "#E044A7"
}
# Création du Marimekko Chart avec couleurs fixes et légende en haut à gauche
fig, ax = plt.subplots(figsize=(12, 8))
# Variables pour positionner les blocs
left = 0
product_positions = {} # Stocker les positions centrales des produits
for produit in df_marimekko["Produit"].unique():
subset = df_marimekko[df_marimekko["Produit"] == produit]
bottom = 0
product_width = subset["width"].sum()
product_positions[produit] = left + product_width / 2 # Position centrale du produit
for _, row in subset.iterrows():
color = segment_colors.get(row["Segment"], "#808080") # Utilisation de la couleur définie ou gris par défaut
ax.bar(left, row["height"], width=row["width"], bottom=bottom, color=color, edgecolor="black")
# Ajout des labels des quantités vendues
ax.text(left + row["width"] / 2, bottom + row["height"] / 2, f"{int(row['Quantites vendues'])}",
ha='center', va='center', fontsize=10, color="black", fontweight="bold")
bottom += row["height"]
left += product_width
# Ajout des labels des produits sous l'axe X
for produit, position in product_positions.items():
ax.text(position, -0.08, produit, ha='center', va='top', fontsize=12, fontweight="bold", color="black", rotation=45)
# Ajout des titres et axes
#ax.set_title("Marimekko Chart - Répartition des Ventes par Produit et Segment", fontsize=14, fontweight="bold")
ax.set_xlabel("Produits (Largeur proportionnelle aux ventes totales)", fontsize=12, labelpad=20)
ax.set_ylabel("Proportion des Ventes (Hauteur = Quantités vendues)", fontsize=12)
# Suppression des ticks pour rendre la visualisation plus propre
ax.set_xticks([])
ax.set_yticks([])
# Ajout d'une légende pour les segments en haut à gauche
handles = [plt.Rectangle((0, 0), 1, 1, color=color, edgecolor="black") for color in segment_colors.values()]
ax.legend(handles, segment_colors.keys(), title="Segments", loc="upper left", bbox_to_anchor=(-0.05, 1.15))
# Affichage
plt.show()
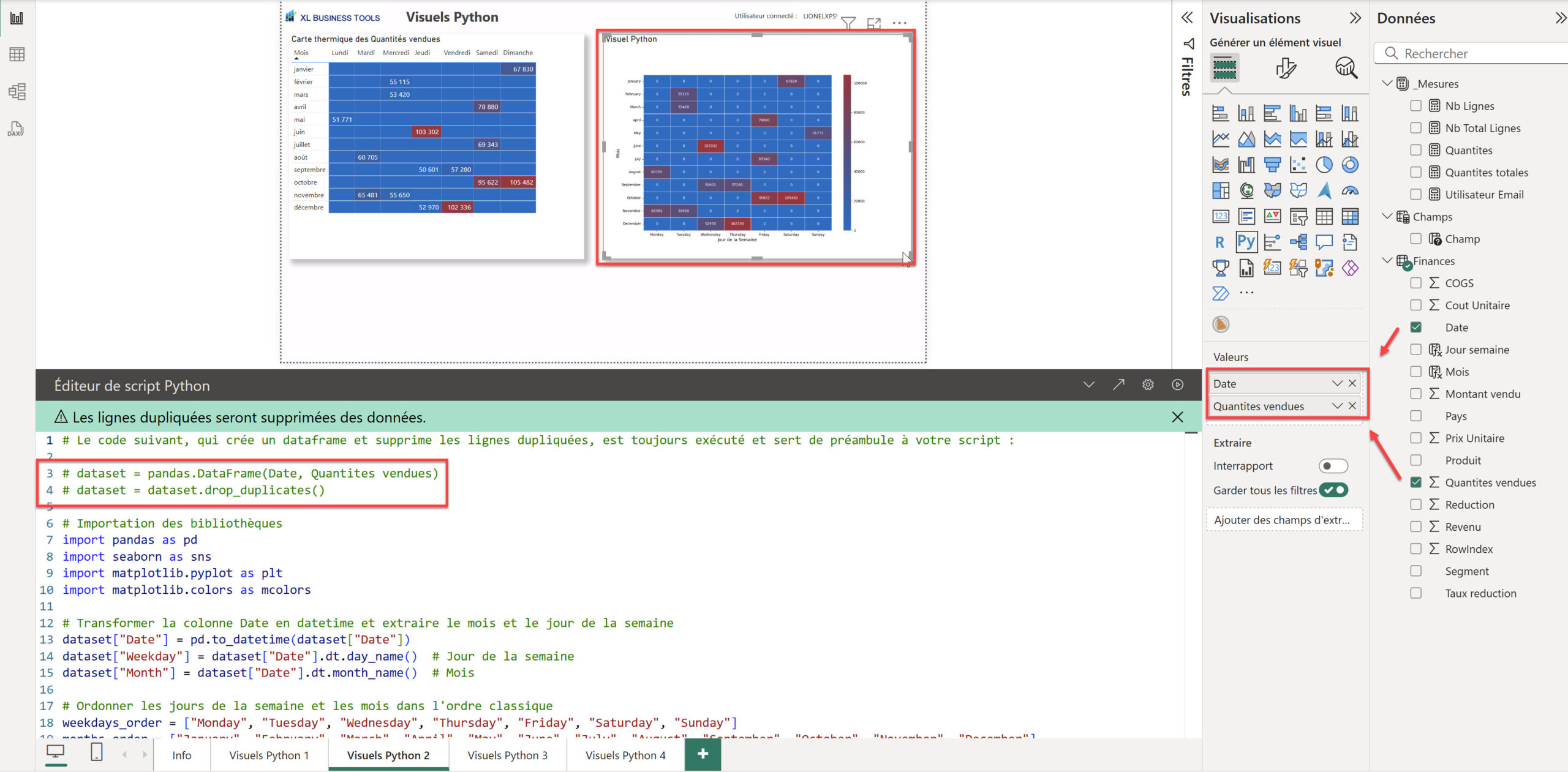
Heatmap
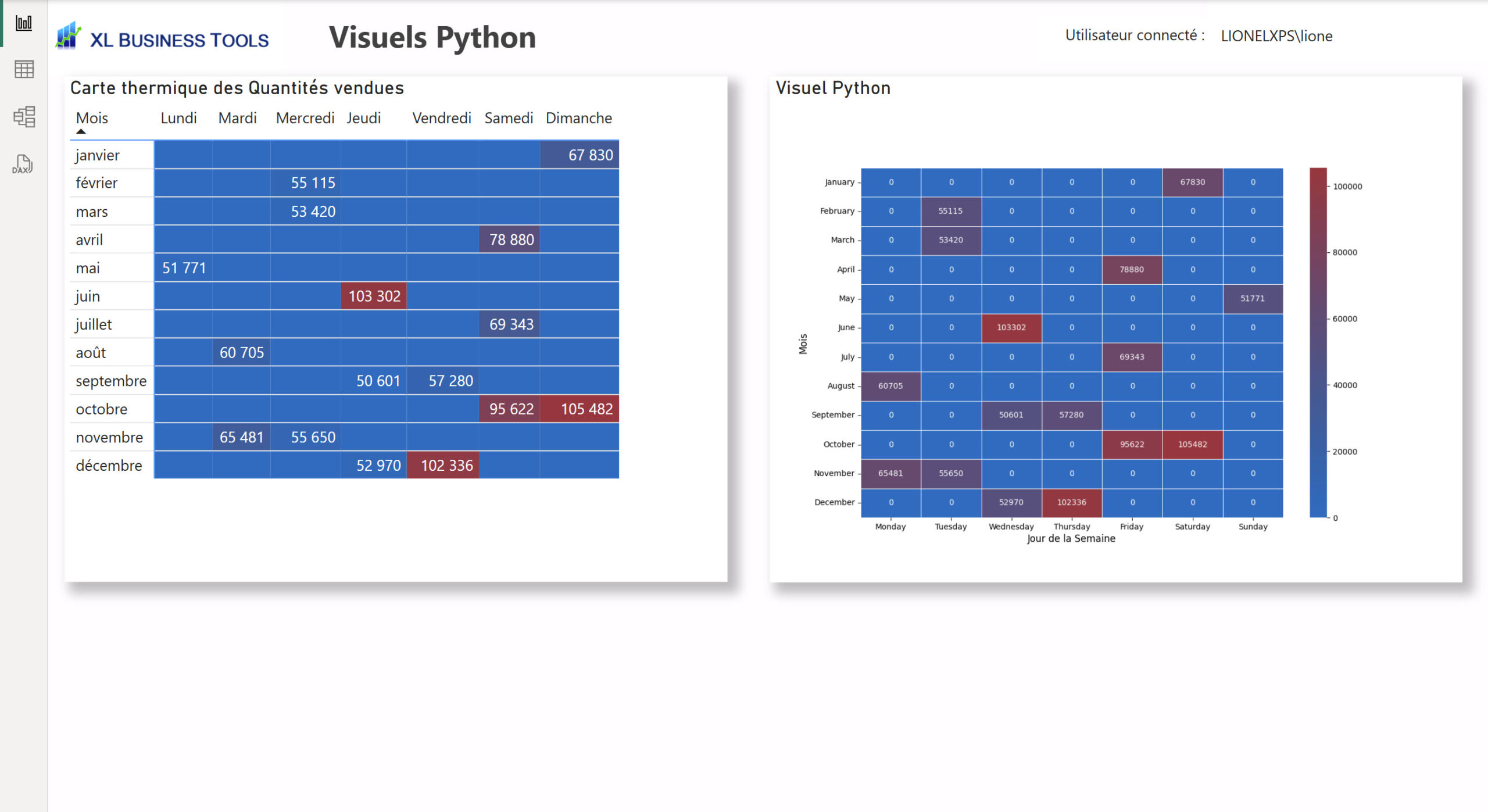
#*****************************************************************************************************
# Visuel Heatmap
#*****************************************************************************************************
# Le code suivant, qui crée un dataframe et supprime les lignes dupliquées, est toujours exécuté et sert de préambule à votre script :
# dataset = pandas.DataFrame(Date, Quantites vendues)
# dataset = dataset.drop_duplicates()
# Importation des bibliothèques
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
# Transformer la colonne Date en datetime et extraire le mois et le jour de la semaine
dataset["Date"] = pd.to_datetime(dataset["Date"])
dataset["Weekday"] = dataset["Date"].dt.day_name() # Jour de la semaine
dataset["Month"] = dataset["Date"].dt.month_name() # Mois
# Ordonner les jours de la semaine et les mois dans l'ordre classique
weekdays_order = ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"]
months_order = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"]
dataset["Weekday"] = pd.Categorical(dataset["Weekday"], categories=weekdays_order, ordered=True)
dataset["Month"] = pd.Categorical(dataset["Month"], categories=months_order, ordered=True)
# Agréger les quantités vendues par Mois et Jour de la semaine
df_heatmap = dataset.groupby(["Month", "Weekday"])["Quantites vendues"].sum().reset_index()
# Pivot pour la heatmap (Mois en Y, Weekdays en X)
heatmap_data = df_heatmap.pivot(index="Month", columns="Weekday", values="Quantites vendues")
# Création d'un colormap personnalisé
cmap = mcolors.LinearSegmentedColormap.from_list(
"custom_cmap", ["#0D6ABF", "#A1343C"] # Valeur min : #0D6ABF, valeur max : #A1343C
)
# Création de la Heatmap avec le colormap personnalisé
plt.figure(figsize=(12, 8))
sns.heatmap(heatmap_data, cmap=cmap, annot=True, fmt=".0f", linewidths=0.5, cbar=True)
# Labels et titre
plt.xlabel("Jour de la Semaine", fontsize=12)
plt.ylabel("Mois", fontsize=12)
#plt.title("Heatmap des Quantités Vendues par Jour de la Semaine et Mois", fontsize=14, fontweight="bold")
# Affichage
plt.show()
Radarplot
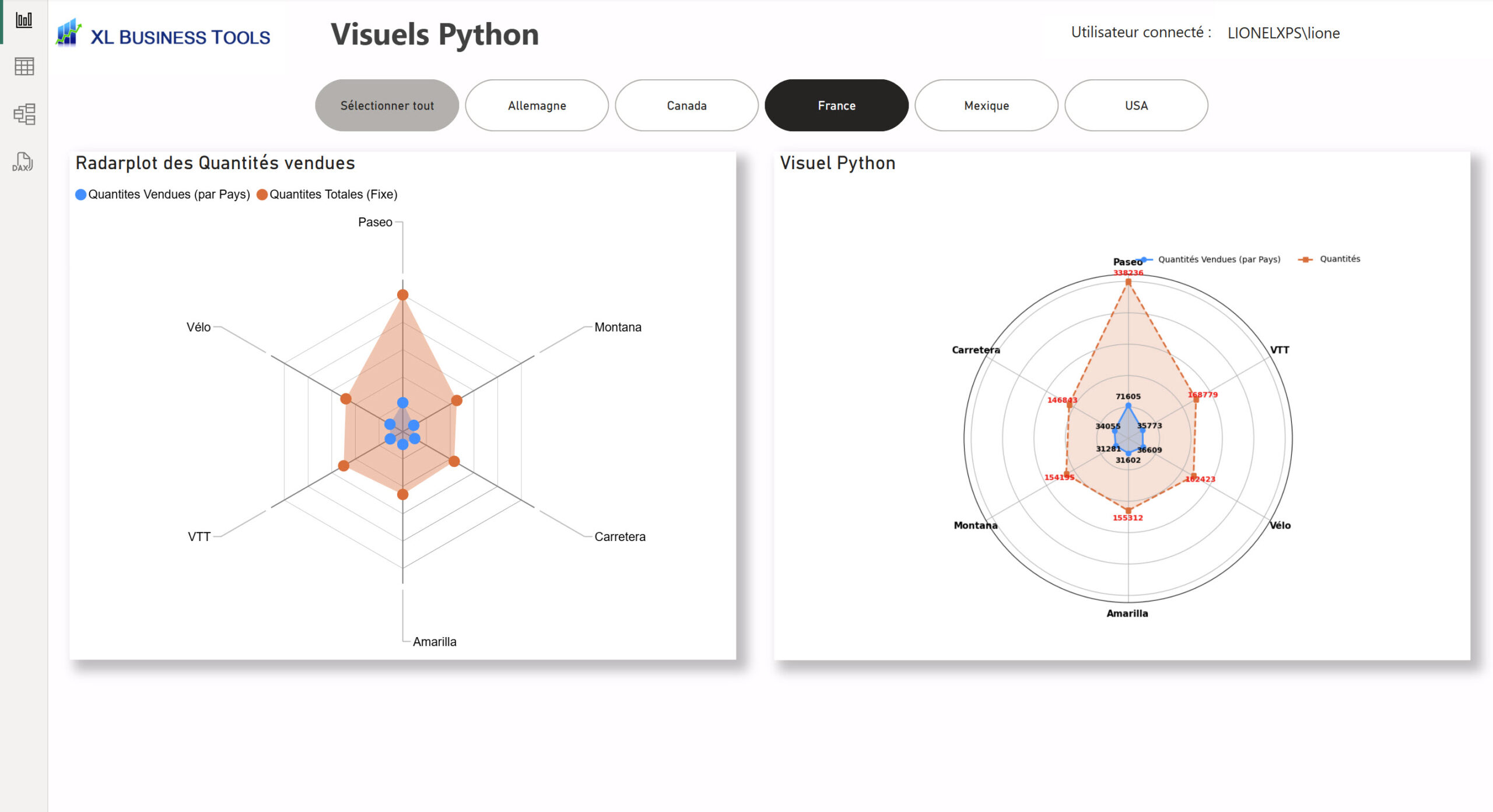
#*****************************************************************************************************
# Visuel Radarplot
#*****************************************************************************************************
# Le code suivant, qui crée un dataframe et supprime les lignes dupliquées, est toujours exécuté et sert de préambule à votre script :
# dataset = pandas.DataFrame(Produit, Quantites, Quantites totales)
# dataset = dataset.drop_duplicates()
# Importation des bibliothèques
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Agréger les données par produit
df_radar = dataset.groupby("Produit")[["Quantites", "Quantites totales"]].sum().reset_index()
# Trier les produits pour un affichage plus clair
df_radar = df_radar.sort_values("Quantites totales", ascending=False)
# Normalisation des valeurs (échelle 0-1)
df_radar["Normalized_Quantites"] = df_radar["Quantites"] / df_radar["Quantites totales"].max()
df_radar["Normalized_Totales"] = df_radar["Quantites totales"] / df_radar["Quantites totales"].max()
# Définition des angles pour le radar plot
labels = df_radar["Produit"].tolist()
values_qte = df_radar["Normalized_Quantites"].tolist()
values_tot = df_radar["Normalized_Totales"].tolist()
angles = np.linspace(0, 2 * np.pi, len(labels), endpoint=False).tolist()
# Fermeture du graphique (première valeur répétée à la fin)
values_qte += values_qte[:1]
values_tot += values_tot[:1]
angles += angles[:1]
# Création du graphique radar
fig, ax = plt.subplots(figsize=(8, 8), subplot_kw=dict(polar=True))
plt.subplots_adjust(top=0.80) # Ajustement pour laisser de l'espace à la légende sous le titre
# Déplacer l'axe au nord**
ax.set_theta_zero_location('N') # 0° placé au nord
ax.set_theta_direction(-1) # Sens horaire
# Tracer les valeurs filtrées (quantités vendues par pays sélectionné)
ax.plot(angles, values_qte, linewidth=2, linestyle="solid", marker="o", color="#118DFF", label="Quantités Vendues (par Pays)")
ax.fill(angles, values_qte, alpha=0.3, color="#118DFF")
# Tracer les valeurs totales (quantités vendues globales)
ax.plot(angles, values_tot, linewidth=2, linestyle="dashed", marker="s", color="#E66C37", label="Quantités Totales (Fixe)")
ax.fill(angles, values_tot, alpha=0.2, color="#E66C37")
# Ajouter les étiquettes des valeurs
for i, angle in enumerate(angles[:-1]): # Exclure la répétition
ax.text(angle, values_qte[i] + 0.05, f"{df_radar['Quantites'].iloc[i]:.0f}",
ha="center", va="center", fontsize=9, fontweight="bold", color="black")
ax.text(angle, values_tot[i] + 0.05, f"{df_radar['Quantites totales'].iloc[i]:.0f}",
ha="center", va="center", fontsize=9, fontweight="bold", color="red")
# Configuration des axes
ax.set_xticks(angles[:-1])
ax.set_xticklabels(labels, fontsize=11, fontweight="bold", rotation=30)
ax.set_yticklabels([]) # Suppression des ticks radiaux
# Ajout d'un titre
#ax.set_title("Radar Plot - Comparaison des Quantités Vendues", fontsize=14, fontweight="bold", pad=60)
# Ajout de la légende entre le titre et la zone graphique sur une ligne
legend = ax.legend(loc="upper left", bbox_to_anchor=(0.5, 1.08), ncol=2, frameon=False, fontsize=10)
# Affichage
plt.show()
And last but not least…
Visuels de distribution des données 💥
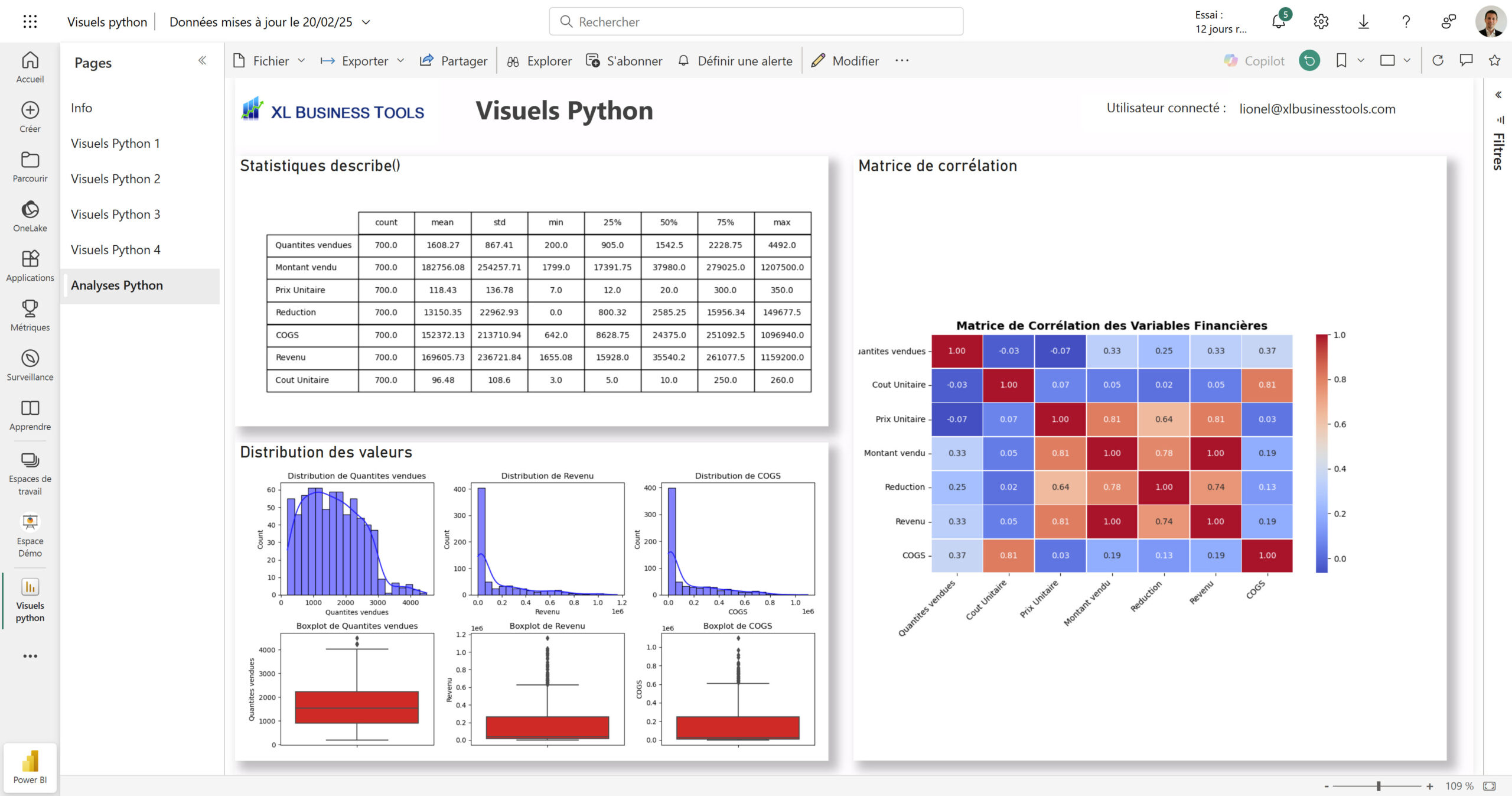
💡Notez que la capture d’écran a été réalisé sur le portail en ligne Power BI Service… et que je n’ai rien eu à configurer, Power BI Service reconnaît le Python 😀
#*****************************************************************************************************
# Distribution des valeurs + Boxplot
#*****************************************************************************************************
import matplotlib.pyplot as plt
import seaborn as sns
# Sélection des colonnes numériques
num_cols = ["Quantites vendues", "Revenu", "COGS"]
# Création de la figure avec plusieurs sous-graphiques
fig, axes = plt.subplots(2, len(num_cols), figsize=(12, 6))
# Tracer les histogrammes et boxplots
for i, col in enumerate(num_cols):
sns.histplot(dataset[col], bins=20, ax=axes[0, i], kde=True, color="blue")
axes[0, i].set_title(f"Distribution de {col}")
sns.boxplot(y=dataset[col], ax=axes[1, i], color="red")
axes[1, i].set_title(f"Boxplot de {col}")
plt.tight_layout()
plt.show()
…Et pour aller plus loin : du Machine Learning avec Python🛸
En utilisant la bibilothèque Scikit-learn de Python, nous pouvons même lancer des mini-modèles de Machine-Learning en temps réel avec les données de notre rapport Power BI.
Voici un exemple pour détecter des anomalies potentielles dans les données de ventes en utilisant l’algorythme Local Outlier Factor.
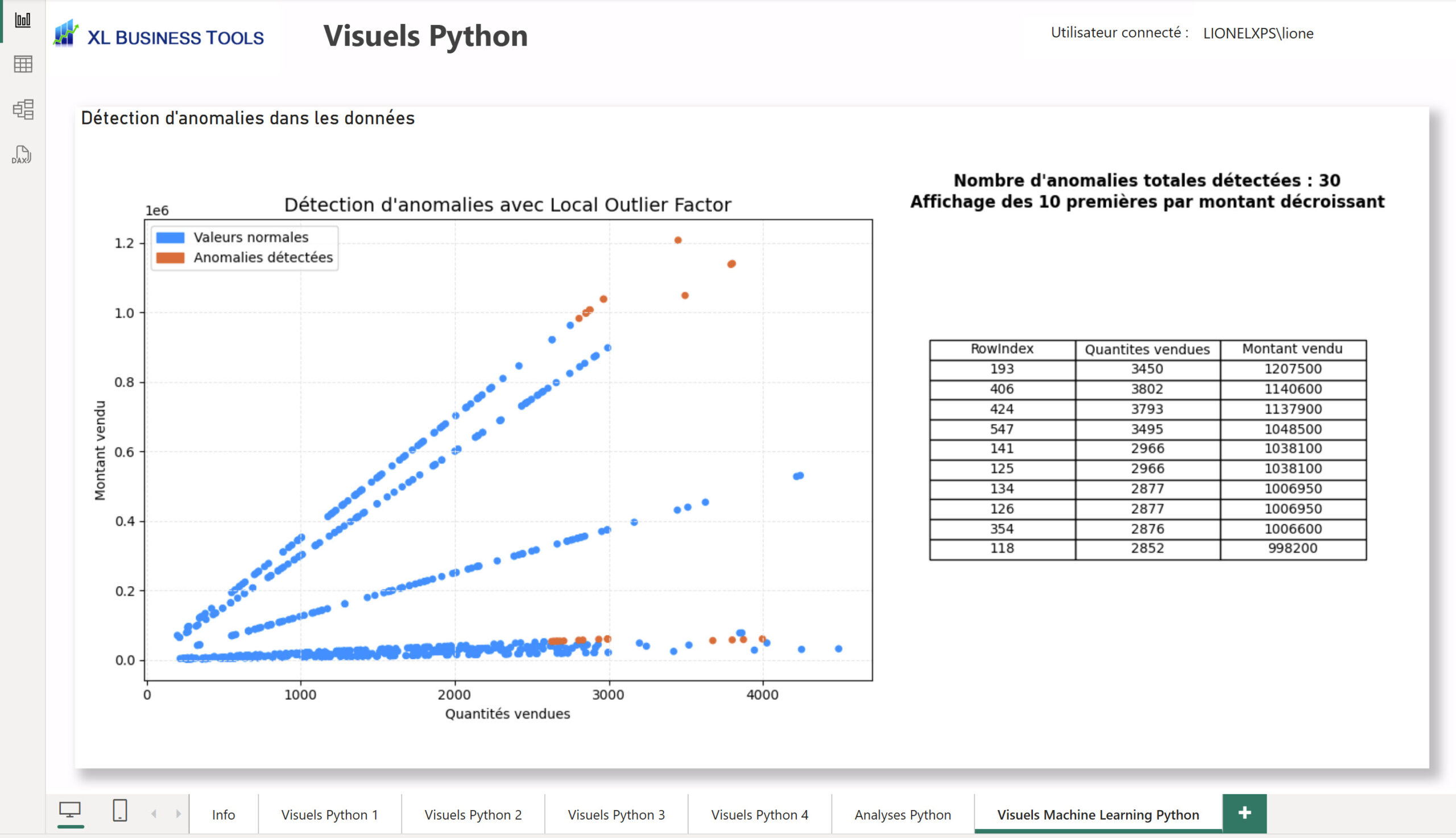
Code Python :
#*****************************************************************************************************
# Détection d'anomalies avec Local Outlier Factor
#*****************************************************************************************************
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.neighbors import LocalOutlierFactor
import matplotlib.patches as mpatches
# 1 - Chargement des données depuis Power BI
df = dataset.copy()
# 2 - Sélection des colonnes et conversion en numérique
df = df[["RowIndex", "Quantites vendues", "Montant vendu"]]
df = df.apply(pd.to_numeric, errors="coerce") # Convertir en valeurs numériques
df = df.dropna() # Supprimer les valeurs manquantes
# 3 - Transformation en tableau numpy
X = df[["Quantites vendues", "Montant vendu"]].values
# 4 - Entraînement du modèle LOF (Détection d’anomalies)
lof = LocalOutlierFactor(n_neighbors=50, contamination="auto")
predictions = lof.fit_predict(X) # -1 = anomalie, 1 = normal
# 5 - Sauvegarde des résultats pour affichage du tableau
df["Anomalie"] = predictions
# 6 - Création de la figure combinée (Graphique + Tableau)
fig, axes = plt.subplots(1, 2, figsize=(14, 6), gridspec_kw={'width_ratios': [2, 1]})
# 6.1 - Graphique des anomalies (à gauche)
ax = axes[0]
colors = {1: "#118DFF", -1: "#E66C37"} # Bleu clair = Normal, Orange = Anomalie
ax.scatter(X[:, 0], X[:, 1], c=[colors[p] for p in predictions], s=20)
# Ajout d’une légende
normal_patch = mpatches.Patch(color="#118DFF", label="Valeurs normales")
anomaly_patch = mpatches.Patch(color="#E66C37", label="Anomalies détectées")
ax.legend(handles=[normal_patch, anomaly_patch])
# Personnalisation du graphique
ax.set_facecolor("white")
ax.grid(color="#E5E5E5", linestyle="--", linewidth=0.7)
ax.set_title("Détection d'anomalies avec Local Outlier Factor", fontsize=14, color="black")
ax.set_xlabel("Quantités vendues", color="black")
ax.set_ylabel("Montant vendu", color="black")
# 6.2 - Tableau des anomalies (à droite)
ax_table = axes[1]
ax_table.axis("off") # Masquer les axes du tableau
# Sélection des anomalies triées par Montant vendu décroissant
anomalies_df = df[df["Anomalie"] == -1].drop(columns=["Anomalie"]).sort_values(by="Montant vendu", ascending=False)
# Nombre total d’anomalies détectées
total_anomalies = anomalies_df.shape[0]
# Sélection des 10 premières anomalies pour affichage
table_data = anomalies_df.head(10).values
columns = list(anomalies_df.columns)
# Ajout d'un titre dynamique au-dessus du tableau
ax_table.text(0.5, 1.1, f"Nombre d'anomalies totales détectées : {total_anomalies}\nAffichage des 10 premières par montant décroissant",
fontsize=12, ha="center", va="top", fontweight="bold", color="black")
# Création du tableau
table = ax_table.table(cellText=table_data, colLabels=columns, cellLoc="center", loc="center")
table.auto_set_font_size(False)
table.set_fontsize(10)
# Ajustement du tableau
table.scale(1.2, 1.2)
# 7 - Affichage final du visuel dans Power BI
plt.tight_layout()
plt.show()
Limitations des visuels Python
Bien entendu, il doit bien y avoir des limitations sinon honnêtement nous passerions tous nos visuels en Python🤓 humm. Voici les plus frustrantes :
- Non-interactivité : Les visuels générés par un script Python sont statiques et il n’est pas possible de filtrer d’autres visuels ou de sélectionner des points. Néanmoins ils sont filtrés par les sélections utilisateurs comme le montre l’animation ci-dessous :
- Limitation du volume de données : Power BI limite la quantité de données envoyée au script Python à 150 000 lignes
- Exécution dépendante de l’environnement :
- Pour Power BI Desktop, vous devez avoir Python installé et configuré correctement.
- Dans Power BI Service, seuls les packages préapprouvés par Microsoft sont disponibles.
- Temps d’exécution : les scripts Python sont plus lents à s’afficher que les visuels natifs ou custom
- La version Mobile des rapports Power BI n’est pas prise en charge actuellement :
La liste complète des limitations est disponible ici.
Et dans Power BI Service ?
Bien que l’installation locale soit obligatoire pour Power BI Desktop, dans le service en ligne Power BI Service, vous n’avez pas besoin d’installer de Gateway personnel pour exécuter du code Python standard. Les packages supportés (comme Matplotlib et Seaborn) sont déjà reconnus par Microsoft.
Conclusion
En fin de compte, Python 🐍 et Power BI forment un duo intéressant pour concevoir des visuels ultra-personnalisés. Et pas besoin d’être un génie du développement et de coder un custom visual pour cela (dans la plupart des cas je dirais) !
- Une grande flexibilité : si un Radarplot ou un autre visuel rare vous fait rêver, c’est possible !
- Quelques précautions : Prévoir l’installation de Python, le respect des packages autorisés, gérer votre frustration concernant les sélections dynamiques, et la gestion du volume de données.
D’ailleurs, Microsoft ne s’arrête pas à Power BI : les notebooks Python dans Fabric et l’intégration de Python dans Excel notamment, cela montre clairement que la frontière entre Data Science et Reporting s’amenuise et qu’apprendre le langage Python sera toujours un atout précieux pour explorer, analyser et visualiser les données💡.
Alors, si vous souhaitez passer à l’étape suivante et créer des rapports réellement hors du commun, découvrez mes formations Power BI.
Cliquez ici pour accéder à la formation complète pour maîtriser Power BI
Bonne exploration !🤩
TELECHARGER LE FICHIER D’EXEMPLE
Téléchargez le fichier Power BI de ce tutoriel.
Entrez votre email pour télécharger le fichier (obligatoire)
Visuels Python dans Power BI
Envoyer le lien de téléchargement à :
Merci d’avoir suivi cet article !!
Expérimentez les visuels Python dans vos propres rapports Power BI et laissez un commentaire sur votre expérience en bas de cet article 😉